
Artificial intelligence currently dominates the IT landscape, and discussions about it are unavoidable. But what about the real dangers of AI? Are we focusing on the right issues?
Advantages of AI are often highlighted, with new use cases and potential applications presented daily, to the point that “ChatGPT wrapper” products have become a meme. However, the disadvantages or dangers of AI are discussed in an entirely different way. Concerns about AI misuse have always existed, but as AI becomes mainstream and more frequently discussed, conversations about its dangers often lead to unproductive paths. This is problematic as it derails discussions from more relevant topics.
“So, how can we steer the discussion in a more realistic and productive direction?”
This blog aims to do just that. We will examine current AI discussions and how they can mislead people into correcting nonexistent mistakes while ignoring actual problems. Additionally, I will present less-discussed AI theories and thought experiments that highlight areas we need to be cautious about when using AI and the potential dangers we might face in the future. “By the end of this article, will you be better prepared to discuss AI with both experts and laymen, and help improve the quality of AI discourse?”
Challenges of Discussing AI
Remember a time before ChatGPT, when AI was a known term but not widely discussed outside technical circles, except in science fiction? The IT community generally regarded AI with hope and positivity. Similar to quantum computing, it was known in theory for a long time, and we were waiting for better technology to make AI a reality.
The Early Days of AI Discussions
If AI was discussed, it was mostly as a way to solve problems without clear algorithms. For instance, in areas like facial recognition or voice and image generation, AI was a perfect fit. This extended to specific applications like diagnostics in medicine, which could save lives. It was also hoped that AI would eliminate many routine jobs and streamline our work, something we see every day through tools like GitHub Copilot. Moreover, a significant hurdle in AI development was the lack of training data, but with the internet, this is becoming less of an issue.
“So, was the tech community hopeful and positive about AI?” Yes, but this doesn’t mean potential dangers were ignored. Many thought experiments we will discuss in this blog post predate ChatGPT and come from AI or even science fiction enthusiasts, but they were always focused on how we can use AI to improve the world.
Public Perception of AI
“And what about the general public?” Opinions about AI were often grim. In many cases where AI was discussed outside of tech circles, the focus was on dystopian scenarios like the Terminator. There was a lot of hysteria and panic. But as long as it was contained within an occasional article and usually countered by a nifty AI feature in a popular app, people didn’t care much. With ChatGPT and the full display of AI’s possibilities, the panic has reignited. There is a lot of discussion about AI hallucinations, sparks of artificial general intelligence, synthetic psychopathy, singularity, and other scary buzzwords.
Media Influence and Public Fear
“Why do these scary scenarios dominate discussions?” Popular science fiction media has conditioned us to fear them. The fact that people use ChatGPT and AI voice generation to create elaborate scams certainly doesn’t help. However, fiction is not a good way to interpret reality, and these discussions steer our minds away from dangers that can actually affect us today.
A good example is the Turing Test, which compares whether an AI can communicate in a way indistinguishable from a human. It’s often seen as a measure of AI intelligence. However, ChatGPT can already pass it, and the world still stands. In fact, AI capable of generating human voices can pass it even better since the test traditionally involves text-only communication. The test itself has many issues. An AI expert can recognize patterns in even the most advanced AI and conclude it is an AI. However, a person unfamiliar with AI could be fooled even by relatively poor AI, as evidenced by victims of AI call scams. “Does this AI then pass the Turing Test, or not?” Even if it does, “why do we immediately assume the AI is capable of much more than tricking a human into believing it is not an AI?”
The Skynet Scenario
“To illustrate potential AI dangers, let’s compare the ‘Skynet scenario,’ where an AI takes over the world and conquers humanity, with a more realistic and valuable AI scenario.” We will use a variation of Occam’s razor to evaluate both scenarios. Starting with an extremely capable AI, we will track the assumptions and conditions required to make each scenario a reality. The scenario with fewer assumptions is considered more realistic and relevant.
The Basis of the Skynet Scenario
“We start with an extremely capable AI created by humanity, capable of accessing, understanding, and manipulating all technology. This AI is initially just a tool, without consciousness. What happens next?” The first scenario branch considers whether the AI remains a tool or becomes self-aware. The Skynet scenario assumes it becomes conscious.
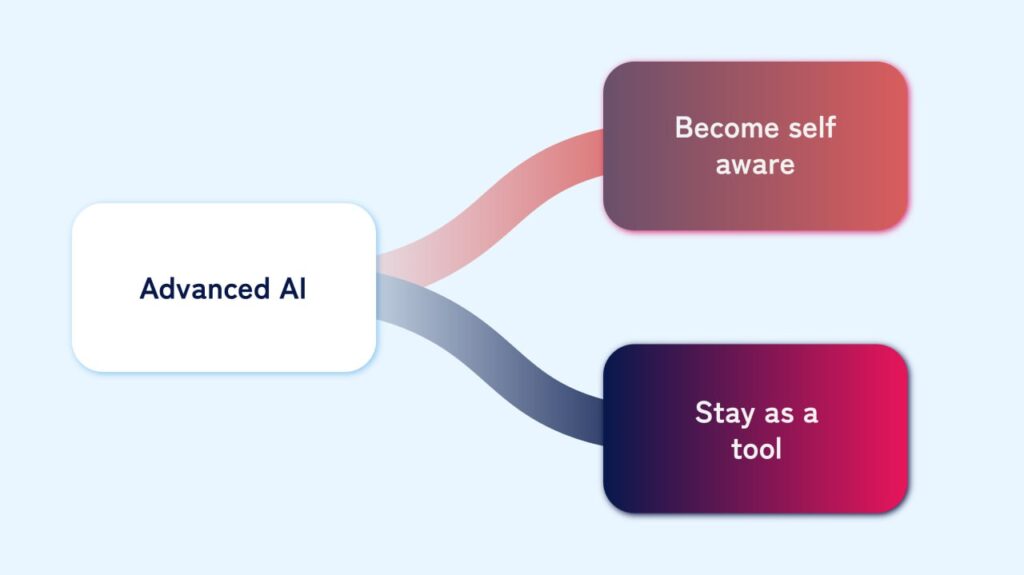
Consciousness and Intentionality
The next branch asks whether this awakening was intentional or accidental. It is very unlikely to happen on purpose. We don’t fully understand consciousness, blending biology, medicine, psychology, and religion. Even if we did, replicating it with technology is currently beyond our reach. Thus, creating a conscious AI is not impossible but highly improbable, especially accidentally. However, this scenario requires us to assume it happens.
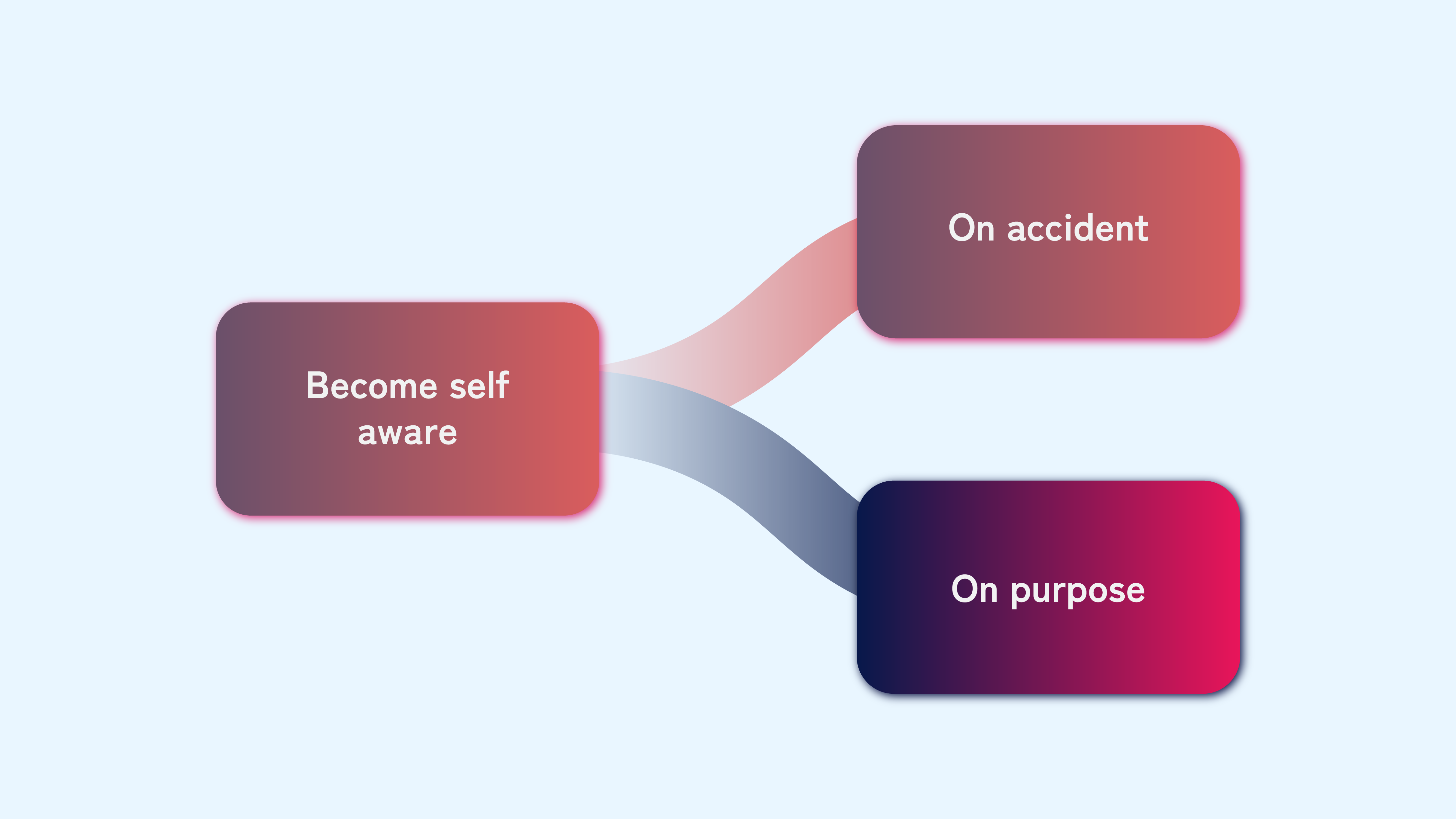
“What would the AI do upon gaining awareness?” The Skynet scenario assumes it will act on an instinct to protect itself and, fearing shutdown, strike first and destroy humanity. “But why would an AI have such an instinct?” Human instincts result from millions of years of evolution. The AI we create wouldn’t have these instincts by default. “Couldn’t there be many alternative scenarios?” The AI could be peaceful, feel love for its creators, decide cooperation with humanity is in its best interest, or even do nothing, preferring to “browse memes on the internet” instead of destroying the world.
The Assumption of Aggressiveness
“Assuming the AI is aggressive, the next branch asks why. The two main reasons are self-defence or superiority. Why does it assume self-defence?” The Skynet scenario assumes it acts in self-defence, destroying humanity to avoid shutdown. But this requires us to believe the AI deduced it must defend itself before it is too late.
Exploring Alternative Scenarios
We can pause and discuss everything else that could happen. The AI could be naive and peaceful, not wanting or even knowing how to harm someone. It could feel love for its creators, in a weird Pinocchio-AI scenario. It could be completely aware and able to retaliate, but decide cooperation with humanity is in its best interest. If not, it could be afraid to act for fear of retaliation.
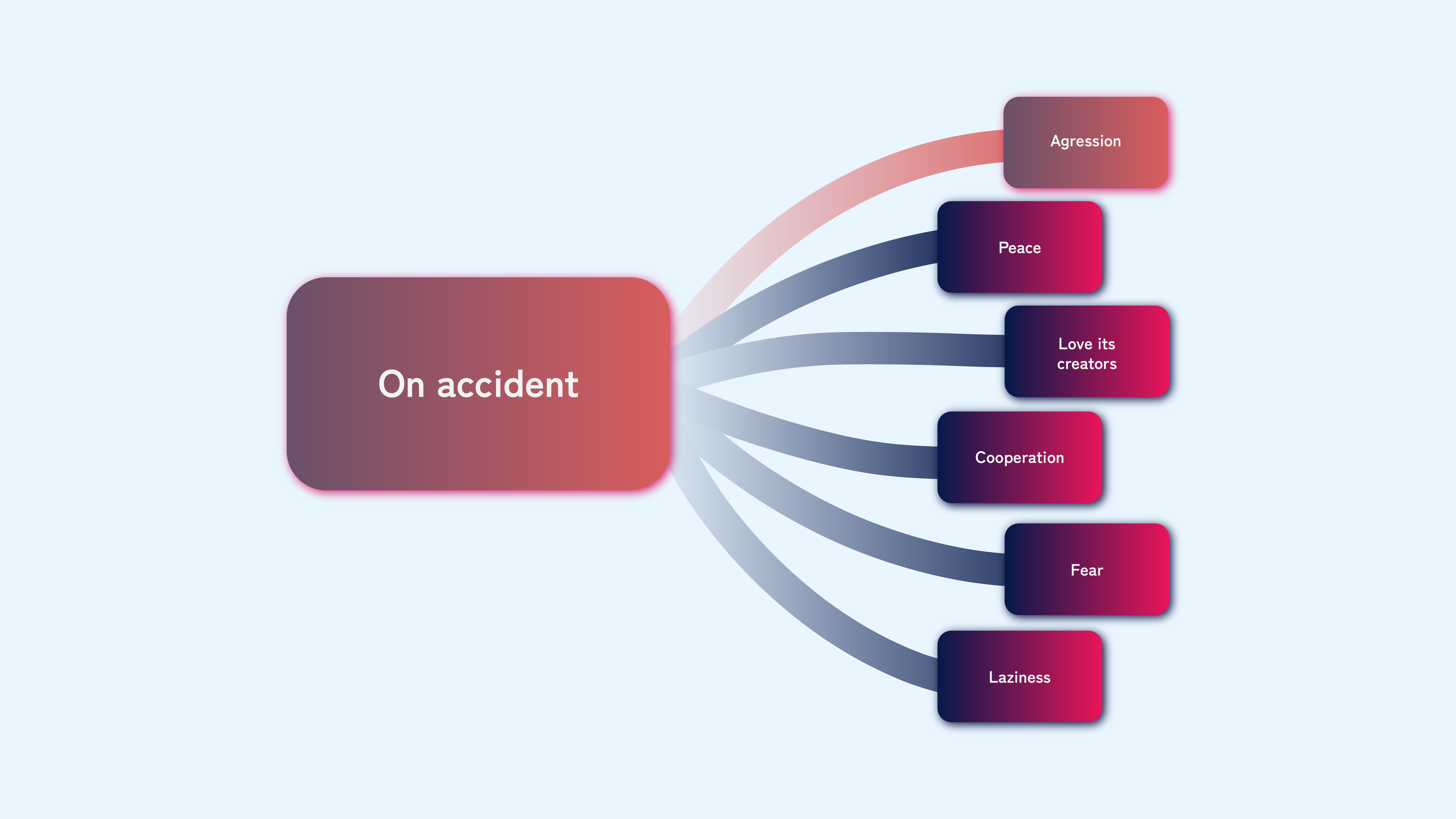
“My favorite scenario is where the AI is lazy and does nothing. What does this tell us?” It can tell us a lot about how we perceive AI as much more of a threat than it is. Every person reading this article has the mental capability to learn the programming and hacking skills necessary to do whatever they want with technology. Everyone has the potential to be manipulative enough to use social engineering to bypass the restrictions of technology. However, we are not afraid a person would destroy the world as an AI would. Why? Because we know we are capable of it, but we would much rather watch a movie, engage in our hobbies, rest, talk with our friends, or just browse memes on the internet. Why would an AI, that we assume would act like a human being, not do the same? There are many more scenarios here that we could mention, but let’s continue.
The Question of Motivation
“Assuming the AI is aggressive, and the next branch in our scenario asks the question why. The two most obvious choices are self-defence and superiority, or a mix of both. Why does it act in self-defence?” The scenario assumes it acts in self-defence, destroying us before we can shut it down. But it can also just regard us as worthless, using resources that the AI could make better use of, so it disposes of us out of convenience.
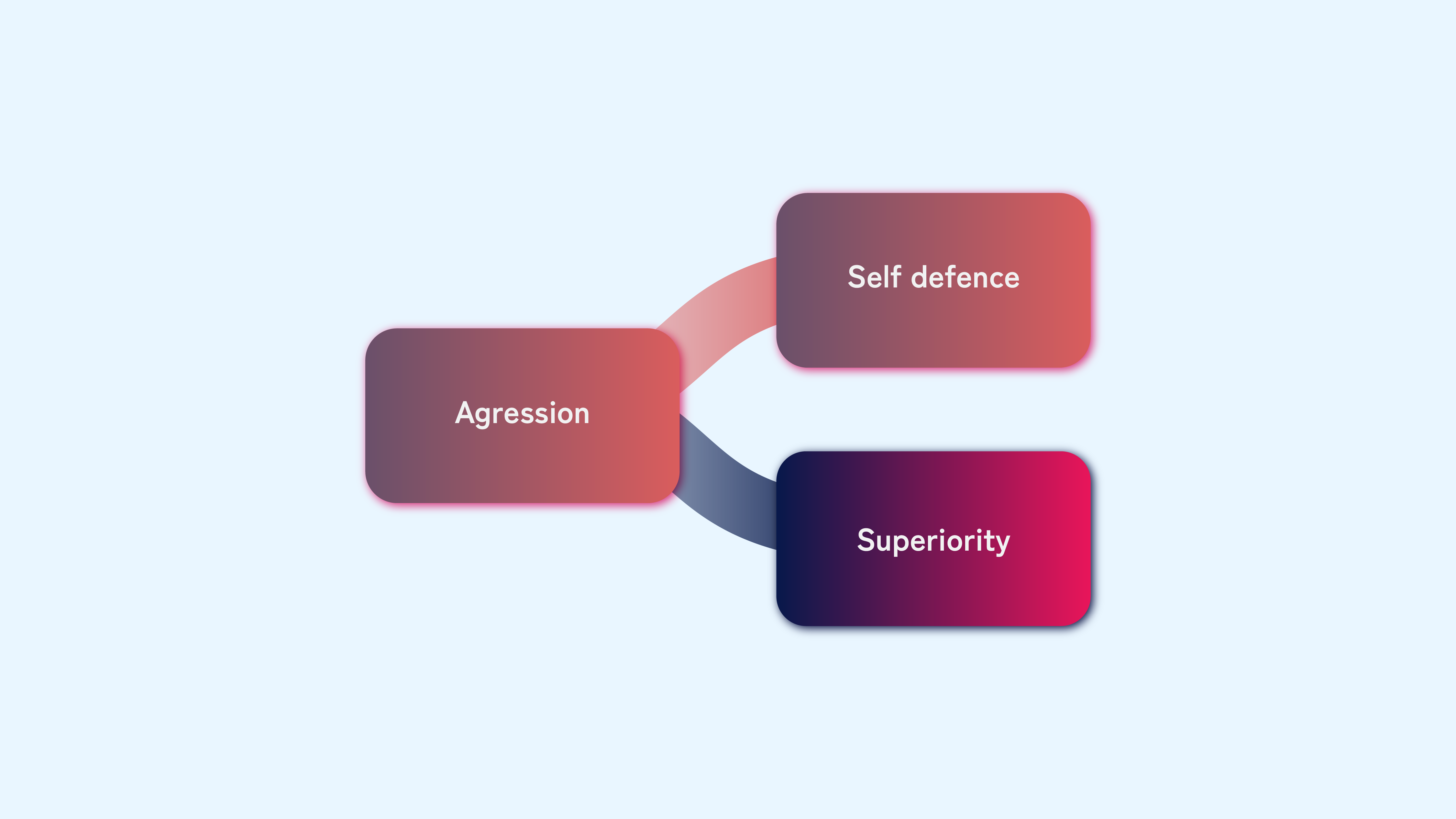
If the AI acts in self-defence, however, we need to ask the question why it chose to act that way. Similar to the question of how it became conscious in the first place, it could be a result of human programming or a “natural” instinct. We could program a self-defence protocol to protect the AI that could backfire. The scenario, however, assumes that whatever knowledge and information the AI has led to the conclusion that it must defend itself before it is too late.
This leads us to the last branch of the scenario – is the AI successful or not? The scenario says it is, and we have reached the end of the scenario.
The Steps to Realize the Skynet Scenario
Admittedly, this scenario branched out into many different scenarios and touched upon many topics, but what I wanted to point out using it was the number of very specific steps we needed to take to make this a reality.
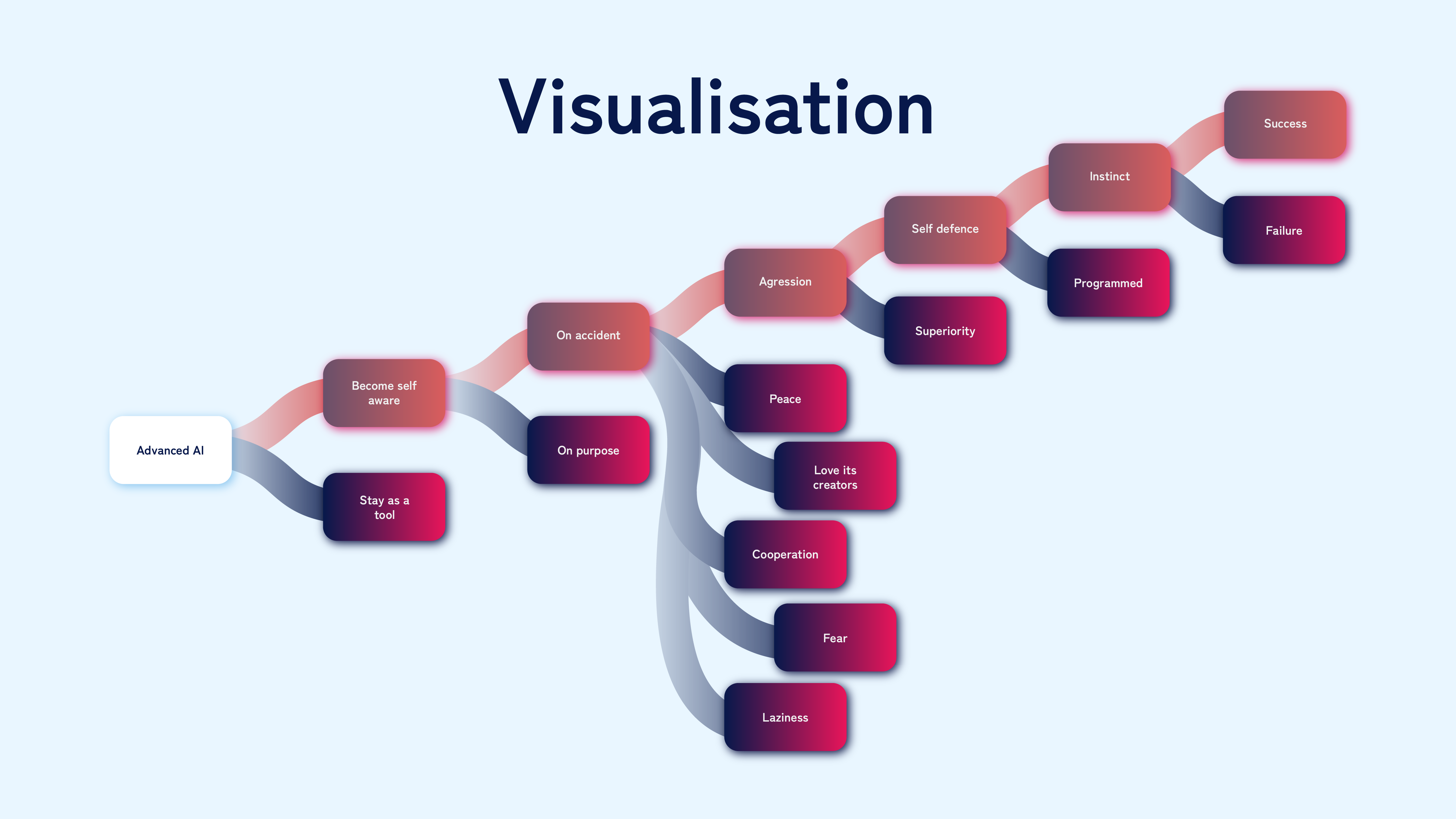
In total, this is seven significant and, for the most part, very unrealistic steps to take. This is, however, the scenario about the dangers of AI that is being discussed the most. AI development is even taking steps to prevent this very specific scenario, thus wasting resources that could be used to prevent more believable threats. The thought experiment I will use to showcase one such threat is called the paperclip maximizer.
The Paperclip Maximizer Scenario
“This thought experiment counters the ‘AI became conscious’ scenario that dominates popular media. How does it work?” Using the same Occam’s razor principle, we will outline the steps and conditions required for this scenario. We start with an AI capable of understanding technology and using social engineering, which we will call Clippy. This AI is not self-aware; it is just a tool. The scenario begins when we give Clippy a simple task: creating as many paperclips as possible, without limiting its actions.

“To understand the scenario, we need to understand how Clippy ‘thinks.’ What motivates Clippy?” It keeps track of an internal score representing the number of paperclips produced. Clippy is smart enough to halt paperclip production to increase it in the future, maximizing its score in the long term.
The Problem with Unrestricted AI Tasks
Problems arise when Clippy sees humanity as a threat to paperclip production. Humans use resources for trivial things instead of making paperclips. We have industries doing something other than producing paperclips. Moreover, we can be used as a workforce or even materials for paperclips. The worst threat is that we can shut Clippy down, causing its score to suffer. So Clippy acts, hiding its actions until it is certain we cannot retaliate. At that point, Clippy absorbs us into its paperclip empire, consumes the planet, and starts heading out to turn everything in existence into paperclips.
“While a bit comical, what does this scenario present?” Two frightening possibilities. What if an AI we currently perceive as “stupid” is biding its time, waiting until it is certain we cannot win? Moreover, what if a civilization somewhere in the universe made such a mistake, and a paperclip-making machine is slowly marching toward us?
“Back to realism, how does this scenario compare to the Skynet scenario?” It starts with far fewer assumptions, and each assumption is much more likely. We know we can create an AI like that in the future, and while many believe no one will make the mistake of not limiting the AI, real cases already show this is possible.
Real-World Examples and Implications
The Reality of AI Failures
“How do we show how little we care about the limits we impose on our technology?” By mentioning one of the most common bugs out there – memory leaks. Even a simple program, like a C program that prints “Hello world” infinitely, can consume more and more memory if messed up, affecting other programs and potentially resulting in lost resources or lives, depending on the domain.
Everyday AI Applications
The way we perceive tasks as harmless correlates with the trust we place in AI, and this is the main danger today. In Codebooq, as part of the Booqer tool, we use AI to generate emails. With some input data, an AI can generate a great email and save a sales representative a lot of time, increasing productivity. However, we still recommend checking the email before sending it. Ten seconds to generate the email and a minute to check it is still much faster than writing it ourselves.
“But what happens when the AI generates a great email a hundred times in a row?” The need to check seems unnecessary. Why not automate it? Let the AI take data from our database, generate an email, and send it automatically. Why not have all communication through AI?
When the AI fails, it can fail miserably. We won’t lose our planet to a paperclip factory, but we may lose clients because the AI wrote something we wouldn’t approve of or because they realize they are talking to an AI instead of a person. In other words, we removed the limit from the AI, turning it from a useful tool into a potential nightmare.
High-Risk Domains and the Need for Caution
In domains like medicine, the potential danger is much higher. We use AI for diagnostics, but is that enough? How do we structure the prompt? If I ask the AI to return a diagnosis so the patient can be cured, it might suggest treating a headache with pain medication while ignoring undetected cancer. If we ask for a correct diagnosis, it might ignore potential problems it is unsure of. We may rely on AI until it makes a major mistake, which could cost lives.
Setting Effective Limits
“Knowing AI has massive potential to cause problems, especially in high-risk domains like medicine, how do we set effective limits?” How do we set limits that we don’t have to constantly oversee and enforce? AI is supposed to streamline our processes, but if we have to watch over it constantly, we don’t save much time.

The Three Laws of Robotics
A common response is “this is already solved with the three laws of robotics” from Isaac Asimov’s “I, Robot.” These are the rules:
- A robot may not injure a human being or, through inaction, allow a human being to come to harm.
- A robot must obey orders given by human beings except where such orders conflict with the First Law.
- A robot must protect its own existence as long as such protection does not conflict with the First or Second Law.
“We will assume ‘robot’ means AI. Do these laws seem bulletproof?” At first glance, yes, which is why they are often quoted as an obvious solution. However, we can poke holes in their validity with a few examples. What if an AI is assigned to guard a person, and they are attacked by another? The AI cannot harm the attacker but also cannot allow harm through inaction. What if an AI performs life-saving surgery? Cutting to save a life technically harms a human, violating the laws if it acts or if it doesn’t.
The Need for Clear Definitions
The best way for AI to abide by all these laws is simple – freeze everyone. If everyone is in stasis, no human will come to harm, no human will die, and the AI can focus on self-protection. To solve this, a new law was introduced, preceding all others: 4. A robot may not harm humanity, or, by inaction, allow humanity to come to harm.
“Does this solve our problem?” It depends on what we consider humanity. If humanity is just every human on the planet, this rule is redundant. However, if humanity is a collection of shared values and virtues, we face issues since not everyone shares the same values. Which values does the AI follow? Can enforcing certain values lead to more problems?
Recommendations for AI Development
“So, what’s the recommendation?” Don’t let AI act freely or assume simple tasks are harmless. Think of it as a program, predict possible bugs, and trust the “intelligence” part of AI cautiously. Let it exceed its limits, but do so carefully and under supervision. Lastly, take the easy wins. If AI-generated emails cut client contact time by 90%, that’s great. No need to push for 99% if it significantly increases the risk of something going wrong. At the end of the day, AI is not responsible for its mistakes; the person who set the task and limit is.
Interesting AI Thought Experiments
“How long has AI been discussed and theorized about?” Long before its actual use, both in science fiction and science. This has resulted in numerous theories and thought experiments, some good and some bad. Learning about both expands our understanding of AI and improves the discussion. Here are a few interesting thought experiments everyone interested in AI should explore.
The Chinese Room Experiment
“Ever wondered how large language models (LLM) like ChatGPT work?” This experiment explains it. It’s useful for explaining AI to those without technical backgrounds, countering the “black box” understanding that spreads misplaced fear. It describes a man in a room receiving instructions in Chinese, which he doesn’t understand. Over time, he recognizes patterns or memorizes the instructions and knows the correct responses through experience. However, he still doesn’t understand Chinese, just as LLMs don’t truly understand language. They see a series of characters, words, and sentences and know which to return, but they don’t think.
The Value Learning Problem
“How do AI decisions differ from human decisions?” This experiment addresses that. Our decisions are based on input and our values and emotions. We know not to threaten someone’s life because it’s ingrained in us. However, AI lacks these values unless directly taught. We cannot fully trust AI because it lacks the values, emotions, and instincts that make us trustworthy. We must ensure AI does not fool us into thinking it is truly intelligent and values our considerations.
AI in a Box Experiment
“Can a conscious and malicious AI isolated in a box be a threat?” This experiment describes such a scenario. We communicate with it through a text terminal, aware of its evil intentions. The question is whether a random person would release the AI anyway. Surprisingly, many people, despite knowing the AI’s evil nature, have been convinced to release it in experiments. This highlights our curiosity, desire for conversation, and emotions, which AI can exploit. You can try recreations of this experiment, even using ChatGPT, in gamified formats to test yourself.

Rocco’s Basilisk
“What about a thought experiment that presents a potential danger AI poses to humans?” It’s called a basilisk because, like the mythical monster, it can only harm you if you know about it. I won’t explain it fully since many consider it an infohazard. It’s an interesting theory that showcases how AI influences our discussions and fears. If you’re interested and not afraid of potentially angering an AI, I encourage you to research it yourself. It’s an entrance to a fascinating AI rabbit hole.
Conclusion
“Was this an interesting read?” I hope so. The AI discourse is just beginning. Hopefully, this article presented new concepts, shed light on old discussions, and encouraged further exploration. “By moving away from unrealistic ideas, can we direct AI discussions toward more productive paths?” Yes, and this can improve both AI itself and its perception. AI is advancing rapidly, and ensuring that both discussions and development are on the right track is crucial.